机器学习特征编码:提升模型性能与数据挖掘技巧
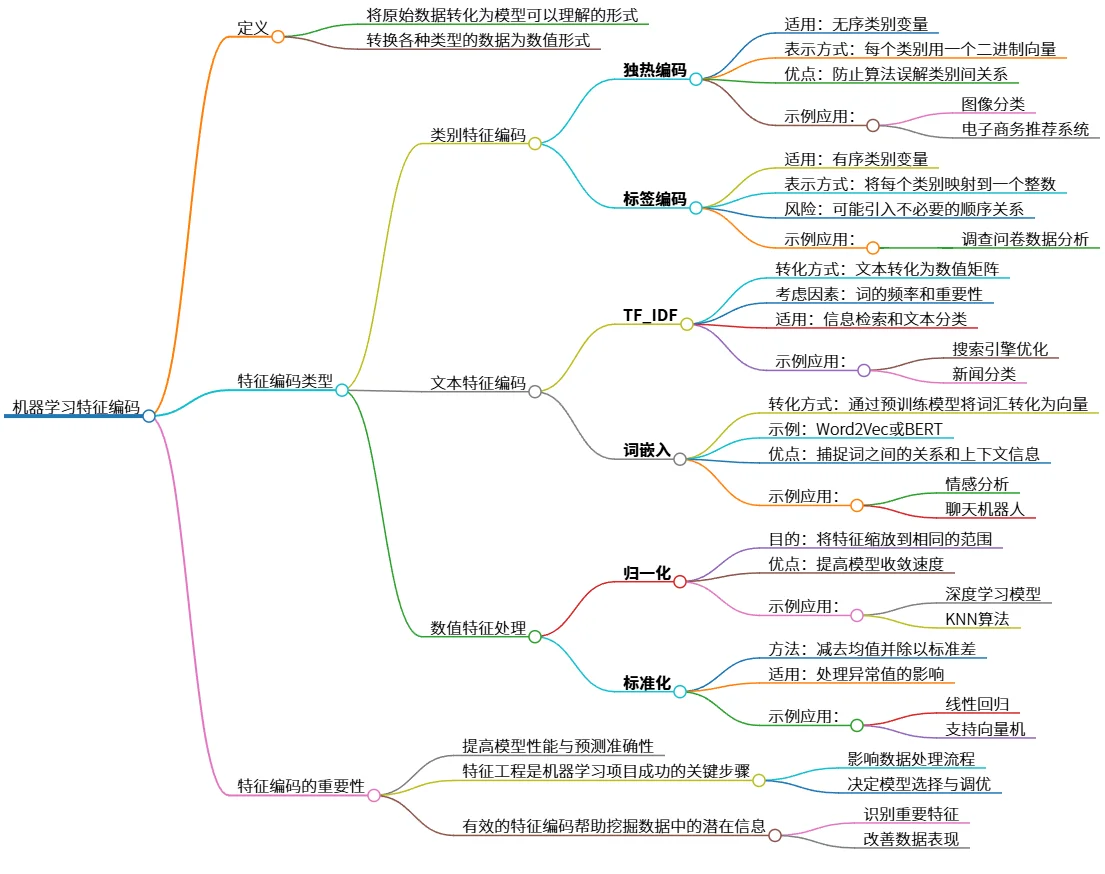
该思维导图介绍了机器学习中的特征编码,包括类别特征编码(独热编码、标签编码)、文本特征编码(TF-IDF、词嵌入)和数值特征处理(归一化、标准化)。特征编码的定义是将原始数据转化为模型可以理解的形式,帮助提高模型性能和预测准确性,突出特征工程在机器学习项目中的关键作用。有效的特征编码能够挖掘数据中的潜在信息。
源码
# 机器学习特征编码
## 定义
- 将原始数据转化为模型可以理解的形式
- 转换各种类型的数据为数值形式
## 特征编码类型
### 类别特征编码
- **独热编码**
- 适用:无序类别变量
- 表示方式:每个类别用一个二进制向量
- 优点:防止算法误解类别间关系
- 示例应用:
- 图像分类
- 电子商务推荐系统
- **标签编码**
- 适用:有序类别变量
- 表示方式:将每个类别映射到一个整数
- 风险:可能引入不必要的顺序关系
- 示例应用:
- 调查问卷数据分析
### 文本特征编码
- **TF_IDF**
- 转化方式:文本转化为数值矩阵
- 考虑因素:词的频率和重要性
- 适用:信息检索和文本分类
- 示例应用:
- 搜索引擎优化
- 新闻分类
- **词嵌入**
- 转化方式:通过预训练模型将词汇转化为向量
- 示例:Word2Vec或BERT
- 优点:捕捉词之间的关系和上下文信息
- 示例应用:
- 情感分析
- 聊天机器人
### 数值特征处理
- **归一化**
- 目的:将特征缩放到相同的范围
- 优点:提高模型收敛速度
- 示例应用:
- 深度学习模型
- KNN算法
- **标准化**
- 方法:减去均值并除以标准差
- 适用:处理异常值的影响
- 示例应用:
- 线性回归
- 支持向量机
## 特征编码的重要性
- 提高模型性能与预测准确性
- 特征工程是机器学习项目成功的关键步骤
- 影响数据处理流程
- 决定模型选择与调优
- 有效的特征编码帮助挖掘数据中的潜在信息
- 识别重要特征
- 改善数据表现
图片