k-近邻算法详解:关键概念、参数选择与应用场景
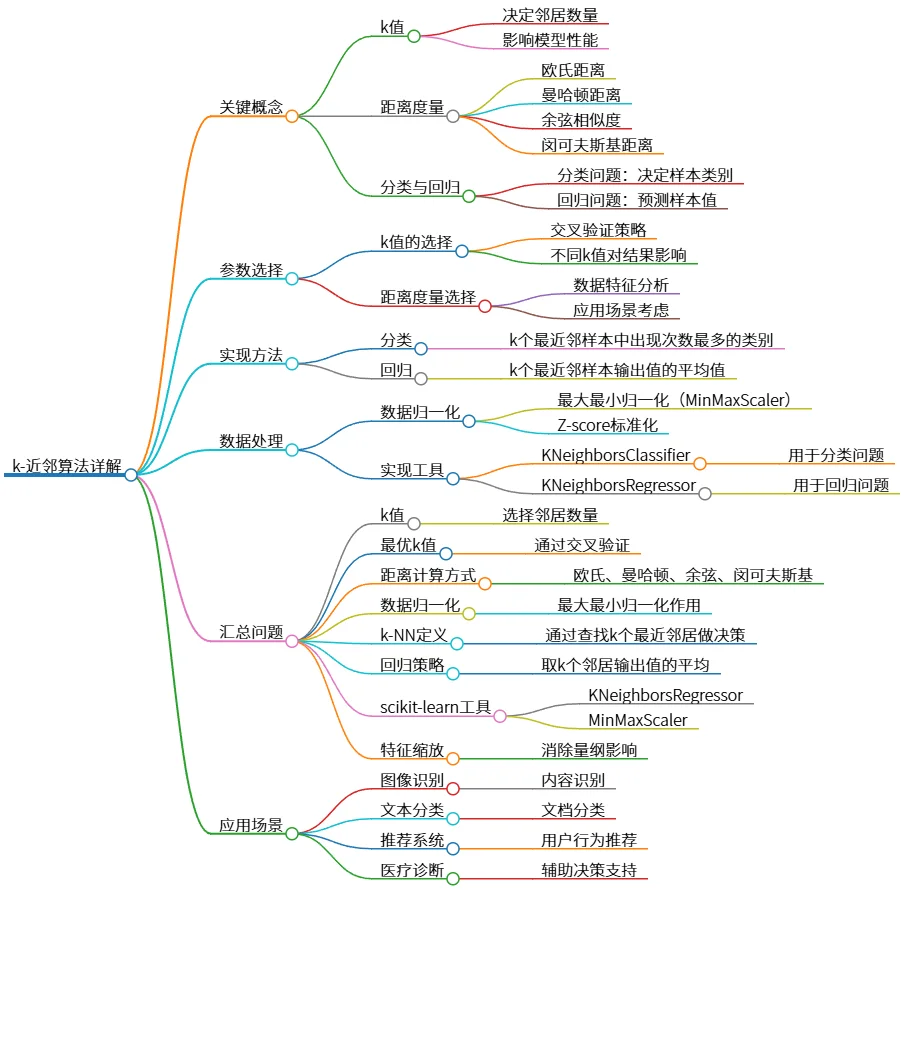
该思维导图概述了k-近邻算法(k-NN)的关键概念,包括k值、距离度量及其在分类和回归中的应用。强调了参数选择的重要性,特别是k值和距离度量的选择。数据预处理如归一化也被提及,特别是使用scikit-learn库的工具,如KNeighborsClassifier和KNeighborsRegressor。最后,列出了k-NN的应用场景,包括图像识别、文本分类、推荐系统和医疗诊断,展示了该算法的广泛适用性。
源码
# k-近邻算法详解
- 关键概念
- k值
- 决定邻居数量
- 影响模型性能
- 距离度量
- 欧氏距离
- 曼哈顿距离
- 余弦相似度
- 闵可夫斯基距离
- 分类与回归
- 分类问题:决定样本类别
- 回归问题:预测样本值
- 参数选择
- k值的选择
- 交叉验证策略
- 不同k值对结果影响
- 距离度量选择
- 数据特征分析
- 应用场景考虑
- 实现方法
- 分类
- k个最近邻样本中出现次数最多的类别
- 回归
- k个最近邻样本输出值的平均值
- 数据处理
- 数据归一化
- 最大最小归一化(MinMaxScaler)
- Z-score标准化
- 实现工具
- KNeighborsClassifier
- 用于分类问题
- KNeighborsRegressor
- 用于回归问题
- 汇总问题
- k值
- 选择邻居数量
- 最优k值
- 通过交叉验证
- 距离计算方式
- 欧氏、曼哈顿、余弦、闵可夫斯基
- 数据归一化
- 最大最小归一化作用
- k-NN定义
- 通过查找k个最近邻居做决策
- 回归策略
- 取k个邻居输出值的平均
- scikit-learn工具
- KNeighborsRegressor
- MinMaxScaler
- 特征缩放
- 消除量纲影响
- 应用场景
- 图像识别
- 内容识别
- 文本分类
- 文档分类
- 推荐系统
- 用户行为推荐
- 医疗诊断
- 辅助决策支持
图片