Ollama本地化部署:大语言模型管理与性能优化指南
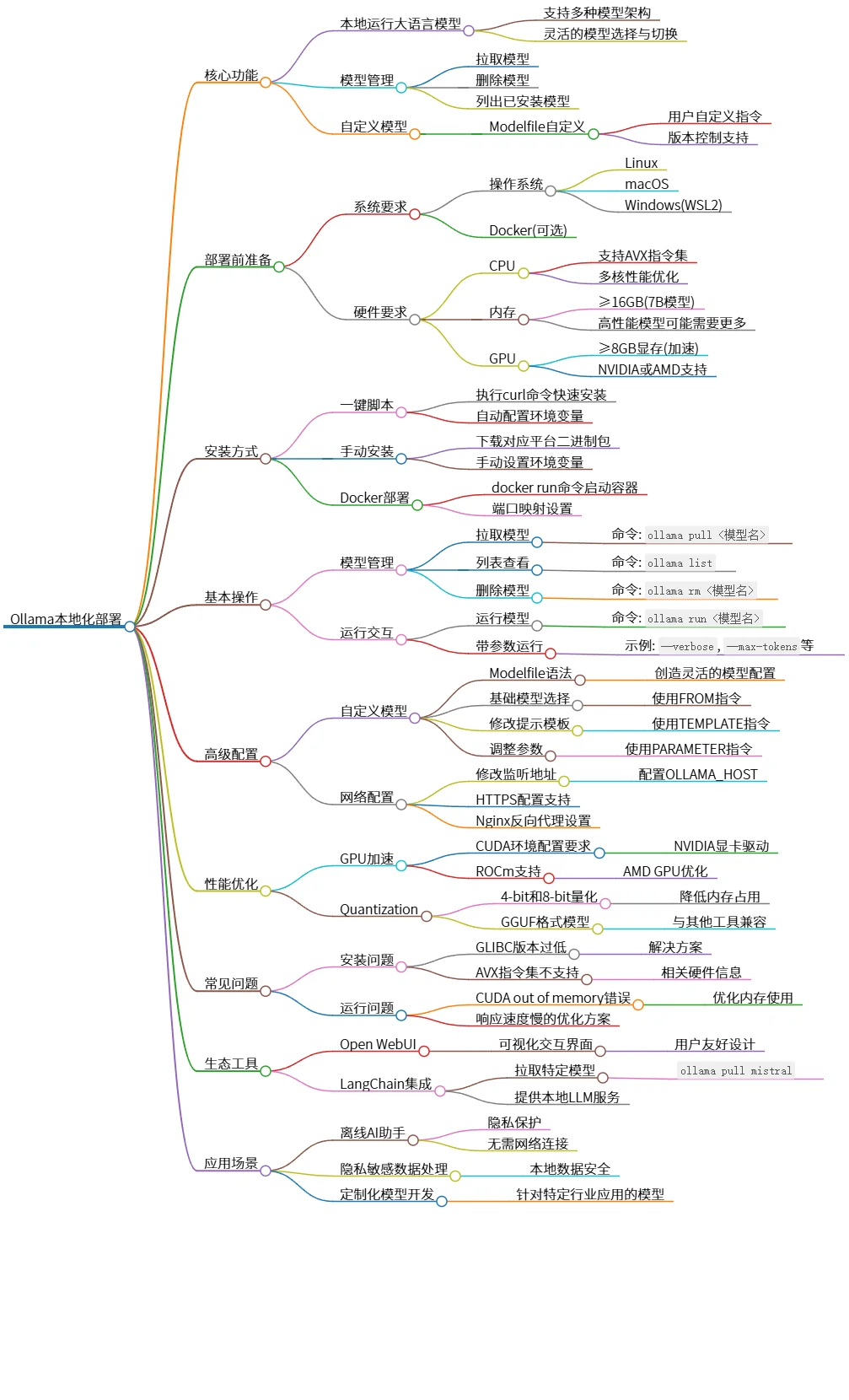
该思维导图描述了Ollama的本地化部署,包括核心功能、部署准备、安装方式、基本操作、高级配置、性能优化、常见问题、生态工具以及应用场景。Ollama允许用户在本地运行大语言模型,提供模型管理及自定义功能,支持GPU加速和量化技术。用户可通过一键脚本或Docker进行安装,并可利用Open WebUI和LangChain等工具进行集成,适用于离线AI助手和数据隐私处理等场景。
源码
# Ollama本地化部署
- 核心功能
- 本地运行大语言模型
- 支持多种模型架构
- 灵活的模型选择与切换
- 模型管理
- 拉取模型
- 删除模型
- 列出已安装模型
- 自定义模型
- Modelfile自定义
- 用户自定义指令
- 版本控制支持
- 部署前准备
- 系统要求
- 操作系统
- Linux
- macOS
- Windows(WSL2)
- Docker(可选)
- 硬件要求
- CPU
- 支持AVX指令集
- 多核性能优化
- 内存
- ≥16GB(7B模型)
- 高性能模型可能需要更多
- GPU
- ≥8GB显存(加速)
- NVIDIA或AMD支持
- 安装方式
- 一键脚本
- 执行curl命令快速安装
- 自动配置环境变量
- 手动安装
- 下载对应平台二进制包
- 手动设置环境变量
- Docker部署
- docker run命令启动容器
- 端口映射设置
- 基本操作
- 模型管理
- 拉取模型
- 命令: `ollama pull <模型名>`
- 列表查看
- 命令: `ollama list`
- 删除模型
- 命令: `ollama rm <模型名>`
- 运行交互
- 运行模型
- 命令: `ollama run <模型名>`
- 带参数运行
- 示例: `--verbose`, `--max-tokens`等
- 高级配置
- 自定义模型
- Modelfile语法
- 创造灵活的模型配置
- 基础模型选择
- 使用FROM指令
- 修改提示模板
- 使用TEMPLATE指令
- 调整参数
- 使用PARAMETER指令
- 网络配置
- 修改监听地址
- 配置OLLAMA_HOST
- HTTPS配置支持
- Nginx反向代理设置
- 性能优化
- GPU加速
- CUDA环境配置要求
- NVIDIA显卡驱动
- ROCm支持
- AMD GPU优化
- Quantization
- 4-bit和8-bit量化
- 降低内存占用
- GGUF格式模型
- 与其他工具兼容
- 常见问题
- 安装问题
- GLIBC版本过低
- 解决方案
- AVX指令集不支持
- 相关硬件信息
- 运行问题
- CUDA out of memory错误
- 优化内存使用
- 响应速度慢的优化方案
- 生态工具
- Open WebUI
- 可视化交互界面
- 用户友好设计
- LangChain集成
- 拉取特定模型
- `ollama pull mistral`
- 提供本地LLM服务
- 应用场景
- 离线AI助手
- 隐私保护
- 无需网络连接
- 隐私敏感数据处理
- 本地数据安全
- 定制化模型开发
- 针对特定行业应用的模型
图片